Examples
All our examples are generated with a single model!
Man-Made Objects

Animals

Humans

Abstract
We present Puppet-Master, an interactive video generative model that can serve as a motion prior for part-level dynamics. At test time, given a single image and a sparse set of motion trajectories (i.e., drags), Puppet-Master can synthesize a video depicting realistic part-level motion faithful to the given drag interactions. This is achieved by fine-tuning a large-scale pre-trained video diffusion model, for which we propose a new conditioning architecture to effectively inject the dragging control. More importantly, we introduce the all-to-first attention mechanism, a drop-in replacement for the widely adopted spatial attention modules, which significantly improves generation quality by addressing the appearance and background issues in existing models. Unlike other motion-conditioned video generators that are trained on in-the-wild videos and mostly move an entire object, Puppet-Master is learned from Objaverse-Animation-HQ, a new dataset of curated part-level motion clips. We propose a strategy to automatically filter out sub-optimal animations and augment the synthetic renderings with meaningful motion trajectories. Puppet-Master generalizes well to real images across various categories, and outperforms existing methods in a zero-shot manner on a real-world benchmark.
Technical Details
Architecture
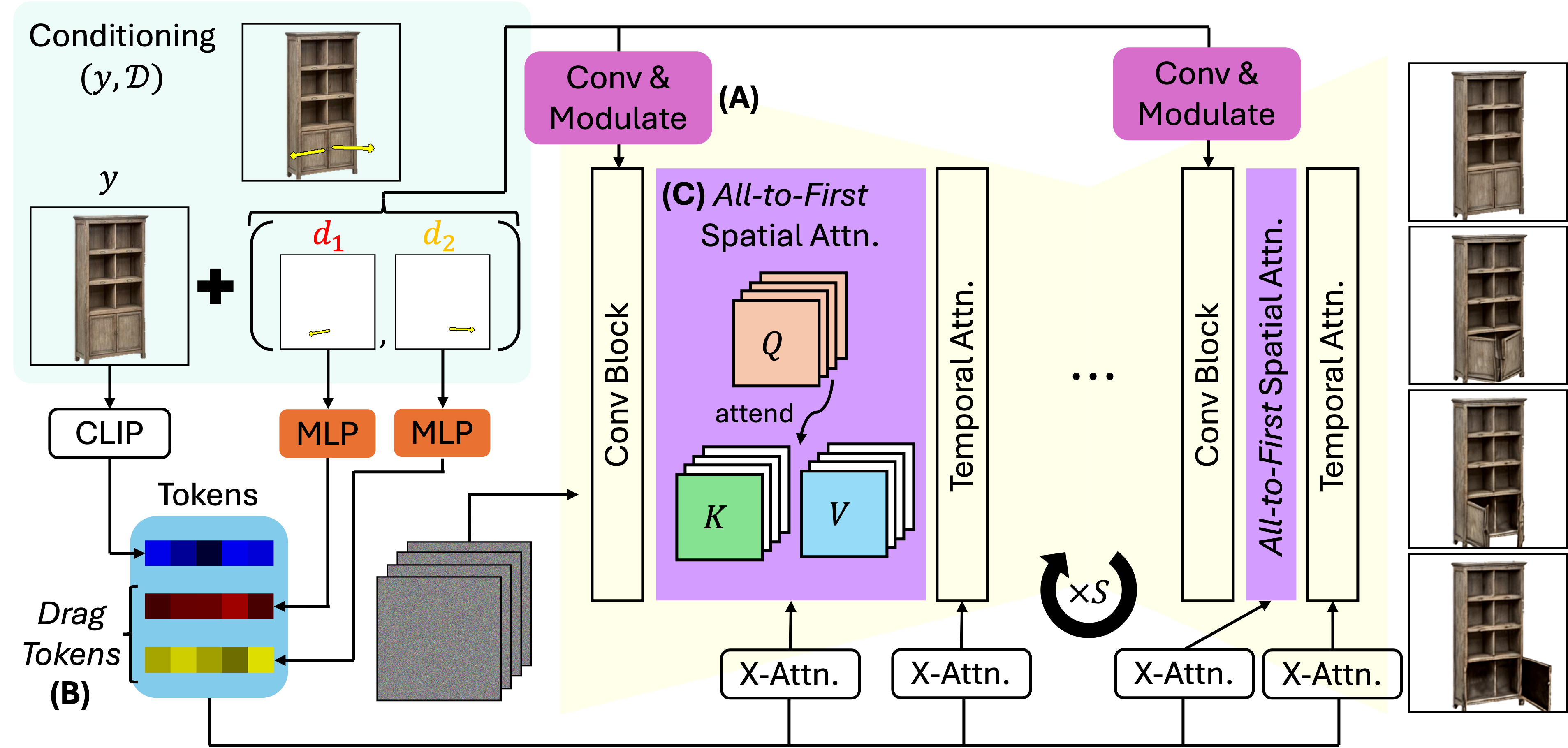
Puppet-Master is built on Stable Video Diffusion (SVD). To enable precise drag conditioning, we first modify the original latent video diffusion architecture by (A) adding adaptive layer normalization modules to modulate the internal diffusion features and (B) adding cross attention with drag tokens. Furthermore, to ensure high-quality appearance and background, we introduce (C) all-to-first spatial attention, a drop-in replacement for the spatial self-attention modules, which attends every noised video frame with the first frame.
Data
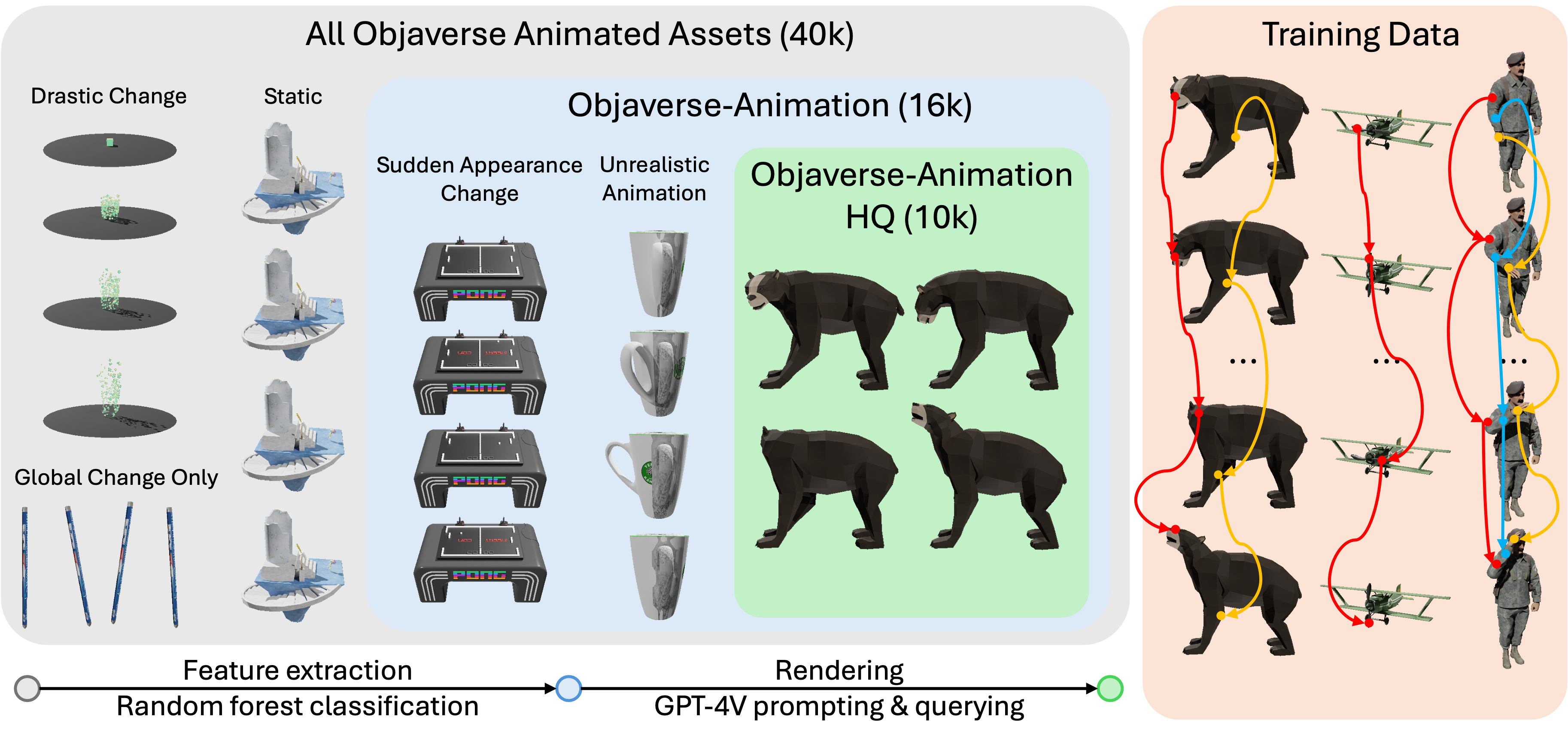
Puppet-Master is trained on a combined dataset of Drag-a-Move and Objaverse-Animation-HQ. We first curate high-quality animated 3D models from Objaverse in two steps: in the first step, we extract important features for each animation and fit a random forest classifier to decide whether an animation should be included in the training set, yielding a dataset of 16K animated models which we dub Objaverse-Animation; in the second step, we prompt GPT-4V to further filter out sub-optimal animations, yielding a higher-quality dataset Objaverse-Animation-HQ consisting of 10K animated models. We augment the animated models with meaningful sparse motion trajectories to train our drag-conditioned video generator. We empirically show that training on Objaverse-Animation-HQ leads to a much better model than training on Objaverse-Animation, justifying the extra efforts in data curation.
BibTeX
@article{li2024puppetmaster,
title = {Puppet-Master: Scaling Interactive Video Generation as a Motion Prior for Part-Level Dynamics},
author = {Li, Ruining and Zheng, Chuanxia and Rupprecht, Christian and Vedaldi, Andrea},
journal = {arXiv preprint arXiv:2408.04631},
year = {2024}
}